使用以下 SQL 创建名为user_log_iceberg的 Iceberg 表并插入一条数据:
create table hadoop_catalog.iceberg_db.user_log_iceberg (
imei string,
uuid string,
udt timestamp
)
using iceberg
partitioned by (days(udt));
insert into hadoop_catalog.iceberg_db.user_log_iceberg values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy', cast(1640966400 as timestamp));
user_log_iceberg 在文件系统中的存储结构为:
user_log_iceberg/
├── data
│ └── udt_day=2021-12-31
│ └── 00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet
└── metadata
├── f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro
├── snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro
├── v1.metadata.json
├── v2.metadata.json
└── version-hint.text
可以看到该表目录下有两个子文件夹:data 和 metadata。其中 data 就是真正的数据文件目录,metadata 是该表的元数据目录,这里的 metadata 就是替代 Hive 中的 Metastore 服务的。
在了解 Iceberg 元数据管理之前先看几个概念:
- SnapshotSnapshot 就是表在某个时间点的状态,其中包括该时间点所有的数据文件。Iceberg 对表的每次更改都会新增一个 Snapshot。
- Metadata File每新增一个 Snapshot 就会新增一个 Metadata 文件,该文件记录了表的存储位置、Schema 演化信息、分区演化信息以及所有的 Snapshot 以及所有的 Manifest List 信息。
- Manifest ListManifest List 是一个元数据文件,其中记录了所有组成快照的 Manifest 文件信息。
- Manifest FileManifest File 是记录 Iceberg 表快照的众多元数据文件的其中一个。其中的每一行都记录了一个数据文件的分区,列级统计等信息。 一个 Manifest List 文件中可以包含多个 Manifest File 的信息。
- Partition Spec表示字段值和分区值之间的逻辑关系。
- Data File包含表中所有行的文件。
- Delete File对按位置或数据值删除的表行进行编码的文件。
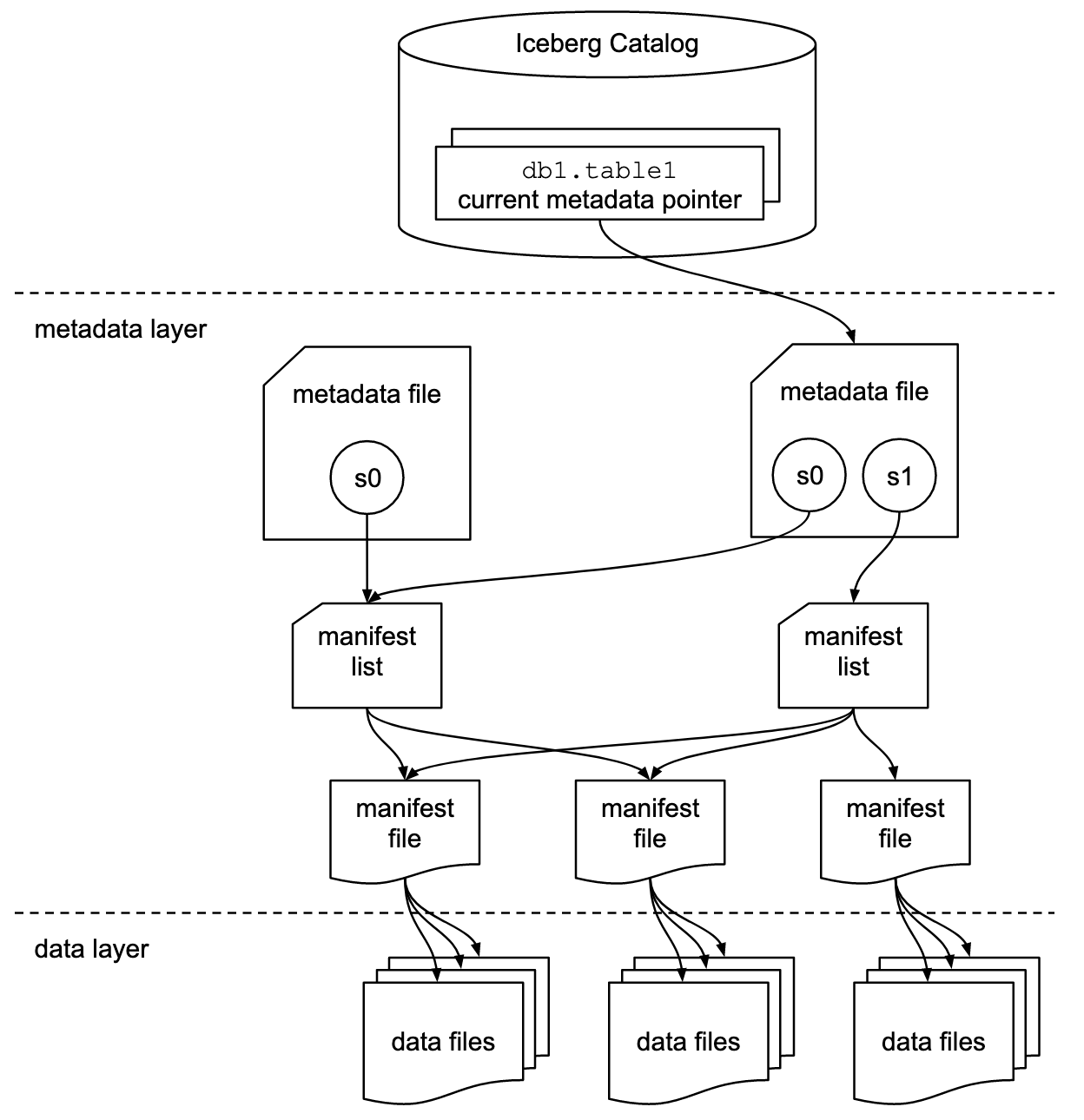
从上图中可以看出 Iceberg 表通过三级关系管理表数据,下面以 Spark 中的 spark.sql.catalog.hadoop_prod.type=hadoop 为例说明。:
最上层中记录了 Iceberg 表当前元数据的版本,对应的是version-hint.text文件,version-hint.text文件中只记录了一个数字表示当前的元数据版本,初始为 1,后续表每变更一次就加 1。
中间层是元数据层。其中 Metadata File 记录了表的存储位置、Schema 演化信息、分区演化信息以及所有的 Snapshot 和 Manifest List 信息,对应的是v1.metadata.json和v2.metadata.json文件,其中v后面的数字和version-hint.text文件中的数字对应,每当新增一个 Snapshot 的时候,version-hint.text中的数字加 1,同时也会新增一个vx.metadata.json文件,比如执行insert into hadoop_catalog.iceberg_db.user_log_iceberg values ('xxxxxxxxxxxxx', 'yyyyyyyyyyyyy', cast(1640986400 as timestamp))、delete from hadoop_catalog.iceberg_db.user_log_iceberg where udt = cast(1640986400 as timestamp)之后,版本就会变成v4:
user_log_iceberg/
├── data
│ └── udt_day=2021-12-31
│ ├── 00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet
│ └── 00000-0-88d582ef-605e-4e51-ba98-953ee3dd4c02-00001.parquet
└── metadata
├── b3b1643b-56a2-471e-a4ec-0f87f1efcd80-m0.avro
├── ecb9255a-bcc5-4954-a4e9-3a54f5b09500-m0.avro
├── f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro
├── snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro
├── snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro
├── snap-8046643380197343006-1-b3b1643b-56a2-471e-a4ec-0f87f1efcd80.avro
├── v1.metadata.json
├── v2.metadata.json
├── v3.metadata.json
├── v4.metadata.json
└── version-hint.text
查看v4.metadata.json中的内容如下:点击查看
{
"format-version": 1,
"table-uuid": "c69c9f46-b9d8-40cf-99da-85f55cb7bffc",
"location": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg",
"last-updated-ms": 1647772606874,
"last-column-id": 3,
"schema": {
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "imei",
"required": false,
"type": "string"
},
{
"id": 2,
"name": "uuid",
"required": false,
"type": "string"
},
{
"id": 3,
"name": "udt",
"required": false,
"type": "timestamptz"
}
]
},
"current-schema-id": 0,
"schemas": [
{
"type": "struct",
"schema-id": 0,
"fields": [
{
"id": 1,
"name": "imei",
"required": false,
"type": "string"
},
{
"id": 2,
"name": "uuid",
"required": false,
"type": "string"
},
{
"id": 3,
"name": "udt",
"required": false,
"type": "timestamptz"
}
]
}
],
"partition-spec": [
{
"name": "udt_day",
"transform": "day",
"source-id": 3,
"field-id": 1000
}
],
"default-spec-id": 0,
"partition-specs": [
{
"spec-id": 0,
"fields": [
{
"name": "udt_day",
"transform": "day",
"source-id": 3,
"field-id": 1000
}
]
}
],
"last-partition-id": 1000,
"default-sort-order-id": 0,
"sort-orders": [
{
"order-id": 0,
"fields": []
}
],
"properties": {
"owner": "PowerYang"
},
"current-snapshot-id": 4140724156423386600,
"snapshots": [
{
"snapshot-id": 6744647507914919000,
"timestamp-ms": 1647758232673,
"summary": {
"operation": "append",
"spark.app.id": "local-1647757937137",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "1032",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "1032",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-6744647507914918603-1-f9d66153-6745-4103-ad24-334fc62f0d1e.avro",
"schema-id": 0
},
{
"snapshot-id": 8046643380197343000,
"parent-snapshot-id": 6744647507914919000,
"timestamp-ms": 1647772293740,
"summary": {
"operation": "append",
"spark.app.id": "local-1647770527459",
"added-data-files": "1",
"added-records": "1",
"added-files-size": "1032",
"changed-partition-count": "1",
"total-records": "2",
"total-files-size": "2064",
"total-data-files": "2",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-8046643380197343006-1-b3b1643b-56a2-471e-a4ec-0f87f1efcd80.avro",
"schema-id": 0
},
{
"snapshot-id": 4140724156423386600,
"parent-snapshot-id": 8046643380197343000,
"timestamp-ms": 1647772606874,
"summary": {
"operation": "delete",
"spark.app.id": "local-1647770527459",
"deleted-data-files": "1",
"deleted-records": "1",
"removed-files-size": "1032",
"changed-partition-count": "1",
"total-records": "1",
"total-files-size": "1032",
"total-data-files": "1",
"total-delete-files": "0",
"total-position-deletes": "0",
"total-equality-deletes": "0"
},
"manifest-list": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro",
"schema-id": 0
}
],
"snapshot-log": [
{
"timestamp-ms": 1647758232673,
"snapshot-id": 6744647507914919000
},
{
"timestamp-ms": 1647772293740,
"snapshot-id": 8046643380197343000
},
{
"timestamp-ms": 1647772606874,
"snapshot-id": 4140724156423386600
}
],
"metadata-log": [
{
"timestamp-ms": 1647757946953,
"metadata-file": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/v1.metadata.json"
},
{
"timestamp-ms": 1647758232673,
"metadata-file": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/v2.metadata.json"
},
{
"timestamp-ms": 1647772293740,
"metadata-file": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/v3.metadata.json"
}
]
}
可以看到snapshots属性中记录了多个 Snapshot 信息,每个 Snapshot 中包含了 snapshot-id、parent-snapshot-id、manifest-list 等信息。通过最外层的 current-snapshot-id 可以定位到当前 Snapshot 以及 manifest-list 文件为/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro。使用java -jar avro-tools-1.11.0.jar tojson snap-4140724156423386841-1-ecb9255a-bcc5-4954-a4e9-3a54f5b09500.avro > manifest_list.json将该文件转换成 json 格式,查看其内容:点击查看
({
"manifest_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/ecb9255a-bcc5-4954-a4e9-3a54f5b09500-m0.avro",
"manifest_length": 6127,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 4140724156423386841
},
"added_data_files_count": {
"int": 0
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 1
},
"partitions": {
"array": [
{
"contains_null": false,
"contains_nan": {
"boolean": false
},
"lower_bound": {
"bytes": "0J\u0000\u0000"
},
"upper_bound": {
"bytes": "0J\u0000\u0000"
}
}
]
},
"added_rows_count": {
"long": 0
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 1
}
},
{
"manifest_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/metadata/f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro",
"manifest_length": 6128,
"partition_spec_id": 0,
"added_snapshot_id": {
"long": 6744647507914918603
},
"added_data_files_count": {
"int": 1
},
"existing_data_files_count": {
"int": 0
},
"deleted_data_files_count": {
"int": 0
},
"partitions": {
"array": [
{
"contains_null": false,
"contains_nan": {
"boolean": false
},
"lower_bound": {
"bytes": "0J\u0000\u0000"
},
"upper_bound": {
"bytes": "0J\u0000\u0000"
}
}
]
},
"added_rows_count": {
"long": 1
},
"existing_rows_count": {
"long": 0
},
"deleted_rows_count": {
"long": 0
}
})
里面包含了两条 json 数据,分别对应了个 Manifest 文件信息,除了 Manifest 文件的路径之外还有一些统计信息。使用java -jar avro-tools-1.11.0.jar tojson f9d66153-6745-4103-ad24-334fc62f0d1e-m0.avro > manifest_1.json和java -jar avro-tools-1.11.0.jar tojson ecb9255a-bcc5-4954-a4e9-3a54f5b09500-m0.avro > manifest_2.json将两个 Manifest 文件转为 json 格式,观察其内容:点击查看
{
"status": 1,
"snapshot_id": {
"long": 6744647507914918603
},
"data_file": {
"file_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/data/udt_day=2021-12-31/00000-0-67ab9286-794b-456d-a1d3-9c797a2b4b03-00001.parquet",
"file_format": "PARQUET",
"partition": {
"udt_day": {
"int": 18992
}
},
"record_count": 1,
"file_size_in_bytes": 1032,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [
{
"key": 1,
"value": 48
},
{
"key": 2,
"value": 48
},
{
"key": 3,
"value": 51
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000@\\CsÔ\u0005\u0000"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000@\\CsÔ\u0005\u0000"
}
]
},
"key_metadata": null,
"split_offsets": {
"array": [4]
},
"sort_order_id": {
"int": 0
}
}
}
{
"status": 2,
"snapshot_id": {
"long": 4140724156423386841
},
"data_file": {
"file_path": "/opt/module/spark-3.2.1/spark-warehouse/iceberg_db/user_log_iceberg/data/udt_day=2021-12-31/00000-0-88d582ef-605e-4e51-ba98-953ee3dd4c02-00001.parquet",
"file_format": "PARQUET",
"partition": {
"udt_day": {
"int": 18992
}
},
"record_count": 1,
"file_size_in_bytes": 1032,
"block_size_in_bytes": 67108864,
"column_sizes": {
"array": [
{
"key": 1,
"value": 48
},
{
"key": 2,
"value": 48
},
{
"key": 3,
"value": 51
}
]
},
"value_counts": {
"array": [
{
"key": 1,
"value": 1
},
{
"key": 2,
"value": 1
},
{
"key": 3,
"value": 1
}
]
},
"null_value_counts": {
"array": [
{
"key": 1,
"value": 0
},
{
"key": 2,
"value": 0
},
{
"key": 3,
"value": 0
}
]
},
"nan_value_counts": {
"array": []
},
"lower_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000\btëwÔ\u0005\u0000"
}
]
},
"upper_bounds": {
"array": [
{
"key": 1,
"value": "xxxxxxxxxxxxx"
},
{
"key": 2,
"value": "yyyyyyyyyyyyy"
},
{
"key": 3,
"value": "\u0000\btëwÔ\u0005\u0000"
}
]
},
"key_metadata": null,
"split_offsets": {
"array": [4]
},
"sort_order_id": {
"int": 0
}
}
}
可以看到,每个 Manifest 文件中的每一行都对应一个 data 目录下的数据文件,除了记录数据文件的路径之外,还记录了该数据文件对应的文件格式、分区信息、以及尽可能详细地记录了各个字段的统计信息、排序信息等。Manifest 文件中的 status,表示此次操作的类型,1 表示 add,2 表示 delete。
可以发现 Iceberg 中对数据文件的管理是文件级别,分区管理、字段统计也是到文件级别,而不是目录级别,这也是为什么 Iceberg 扫描要比 Hive 快的原因。在扫描计划里,查询谓词会自动转换为分区数据的谓词,并首先应用于过滤数据文件。接下来,使用列级值计数、空计数、下限和上限来消除无法匹配查询谓词的文件,在某些情况下可以提升数十倍效率。
但是由于 Iceberg 用 json 文件存储 Metadata,表的每次更改都会新增一个 Metadata 文件,以保证操作的原子性。历史 Metadata 文件不会删除,所以像流式作业就需要定期清理 Metadata 文件,因为频繁的提交会导致堆积大量的 Metadata。可以通过配置write.metadata.delete-after-commit.enabled和write.metadata.previous-versions-max属性实现自动清理元数据。
提示
前面是以 spark.sql.catalog.hadoop_prod.type=hadoop举例,如果 spark.sql.catalog.hadoop_prod.type=hive,文件组织方式会稍有不同,如:
- 没有
version-hint.text文件,而是通过 Metastore 服务来记录当前版本指针; - Metadata File 的命名不再是
vx.metadata.json的方式,.metadata.json前面的vx部分将是一个很长的 UUID。
from:https://www.sqlboy.tech/pages/19baa8/