跳到内容
跳到主菜单
技术派
菜单
关闭
又一个专业分享技术的网站
欢迎光临,关于我们…
搜索结果:
搜索
近期文章
归因分析-待整理
【Doris 全面解析】存储层设计介绍 2——写入流程、删除流程分析
【Doris全面解析】存储层设计介绍1——存储结构设计解析
hive 响应慢问题定位
基于doris+es 搭建用户画像系统(待整理)
近期评论
文章归档
2025年5月
2024年11月
2021年5月
2021年4月
2021年1月
2020年11月
2020年7月
2020年2月
2019年4月
2019年1月
2018年12月
分类目录
ClickHouse
doris
Flink
Hadoop
HBase
hive
Java
Spark
大厂开发知识
大厂运维知识
大厂项目知识
开发技巧
数据仓库建设
未分类
功能
登录
文章
RSS
评论
RSS
切换搜索区域
又一个专业分享技术的网站
欢迎光临,关于我们…
搜索结果:
搜索
近期文章
归因分析-待整理
【Doris 全面解析】存储层设计介绍 2——写入流程、删除流程分析
【Doris全面解析】存储层设计介绍1——存储结构设计解析
hive 响应慢问题定位
基于doris+es 搭建用户画像系统(待整理)
近期评论
文章归档
2025年5月
2024年11月
2021年5月
2021年4月
2021年1月
2020年11月
2020年7月
2020年2月
2019年4月
2019年1月
2018年12月
分类目录
ClickHouse
doris
Flink
Hadoop
HBase
hive
Java
Spark
大厂开发知识
大厂运维知识
大厂项目知识
开发技巧
数据仓库建设
未分类
功能
登录
文章
RSS
评论
RSS
切换搜索区域
搜索结果:
搜索
隐藏搜索覆盖
归因分析-待整理
发布日期
2025年5月14日
评论
0
【Doris 全面解析】存储层设计介绍 2——写入流程、删除流程分析
发布日期
2024年11月12日
评论
0
【Doris全面解析】存储层设计介绍1——存储结构设计解析
发布日期
2024年11月12日
评论
0
hive 响应慢问题定位
发布日期
2021年5月6日
评论
0
基于doris+es 搭建用户画像系统(待整理)
发布日期
2021年4月23日
评论
0
sqoop用法之mysql与hive数据导入导出
发布日期
2021年1月31日
评论
0
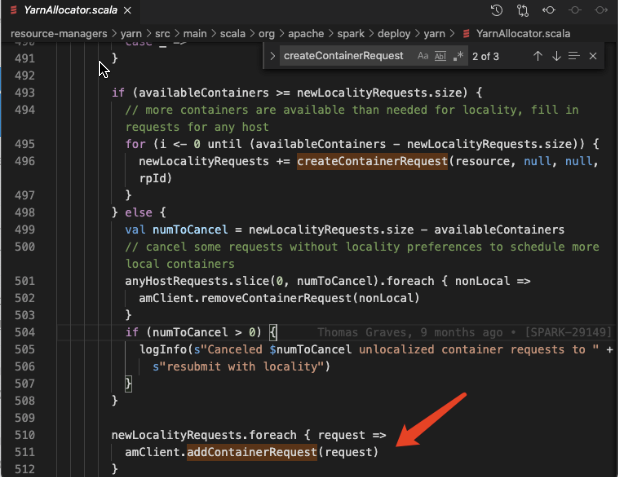
Spark提交任务流程
发布日期
2020年11月20日
评论
0
Clickhouse 性能问题分析(一)zk报连接异常,性能低下
发布日期
2020年11月19日
评论
0
hive任务结束了,但是hive终端或者命令行没退出
发布日期
2020年11月19日
评论
0
【原创】几句话说清楚《HBASE Snapshot 恢复 restore 原理》
发布日期
2020年7月1日
评论
0
加载更多
没有更多的加载。
下一页 →








近期评论