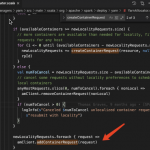
Spark 调用了 AmRmClient 的 API addContainerRequest
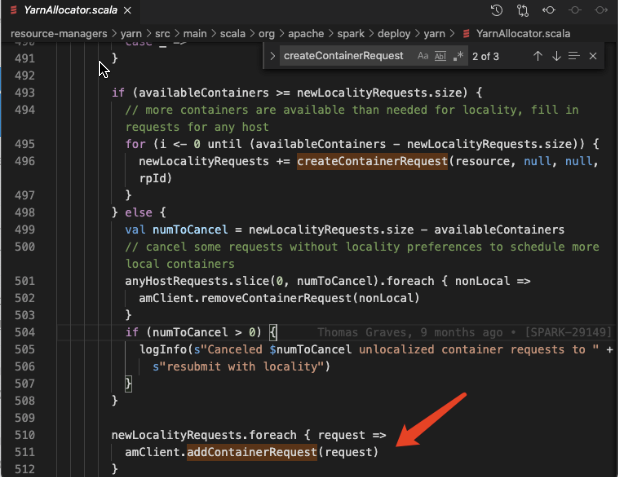
AmRmClient 在处理 addContainerRequest 时,会针对每个 ContainerRequest 生成一个ResourceRequest
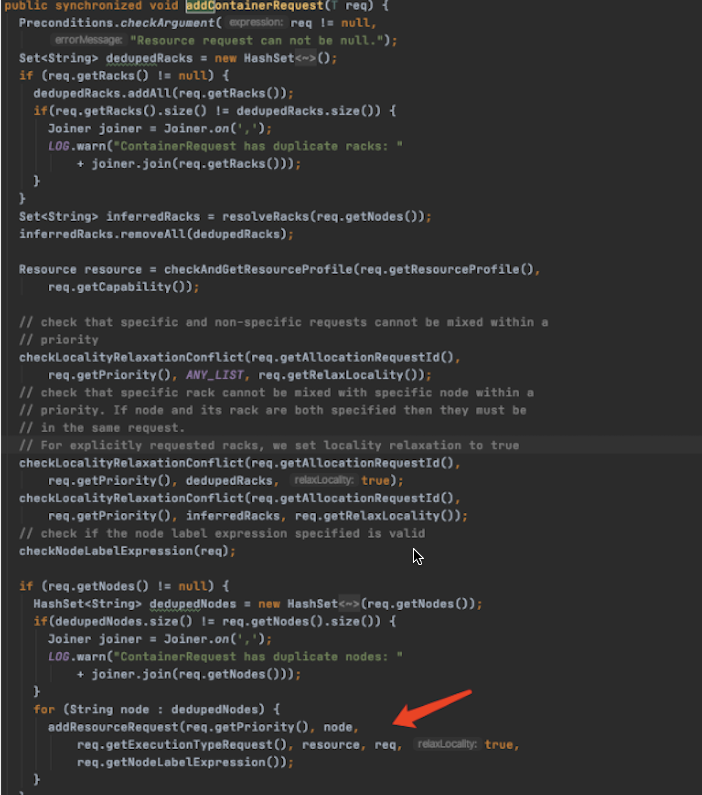
但是 ResourceRequest 接下来是由为 ResourceRequestInfo 处理的,这个是缓存在 (priority, resourceName, executionType) 三元组为 key 的 map 中的,每次取到了都会重新 set labelExpression。尽管 labelExpression 这里被 random 处理了,但只保留了最后一次。
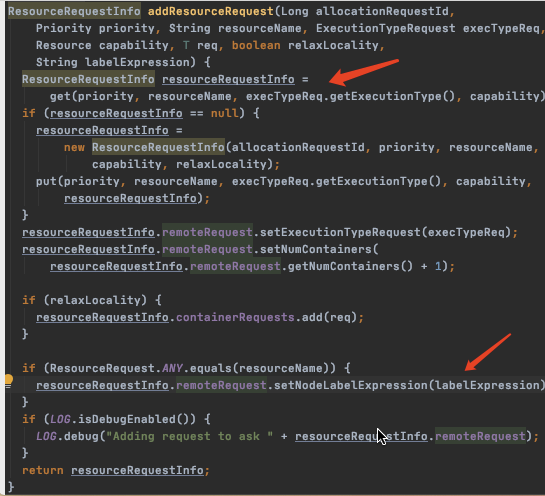
问:是否可以把 ResourceRequestInfo 的 map 多加一层 label的,这样就能保留每次不同的 labelExpression 了?
答:应该是am去申请的container的时候,标签是随机的,一半提交到了资源紧张的分区,被pending了,客户端因为conainer已经申请完了,不会新申请container,这里要看看yarn有没有重新申请conainer的能力,如果pengding超过一定时间
问:但是我理解每次 assignContainerToNodes 都是以 nm node 为单位的哈,1500台 nm 的集群都没有资源在pending,只分配到小集群的概率太小了,应该不会稳定地出现一边倒的情况。上面分析的结论是,多个 containerRequest 会被合并成一个,所以只带了一个标签。
答:现在现象是长尾任务containaienr都pengding在资源比较少的那些分区是吧。所有的containerrequest本来就是一批哈 咱们这做的就是APP的container分配到同一个区分。
问:短任务也会,长任务时间长了可以跑满到所有分区。猜测是后面几个 stage 对应的request成功分配到了默认分区里。这个可能咱们还得对一下,不然有些典型场景可能会有问题哈。比如如果默认分区几乎跑满了,刚刚弹性扩容出来的分区是空的,所有任务仍然只有一半概率跑到扩容出来的分区上,除非默认分区 100% pending,才有可能在重试的时候都跑到新分区上去。同理,如果倒换过来,一个超过了弹性分区可用资源规模的任务调度到了弹性分区上,也有可能导致一些问题。我理解这种模式可能适合大量的小任务,但是大任务有较小任务更大的概率会变得更慢。




近期评论