
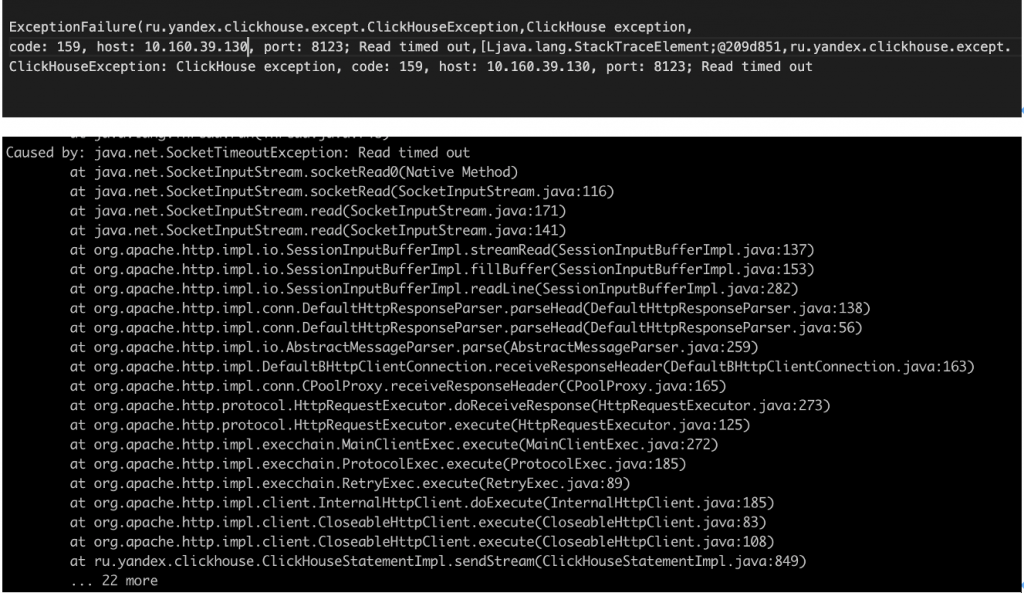
原因分析:
table read only 跟 zk 也有直接关系。现在能肯定 zk 集群的性能跟不上么 ?在这个压力下只要错误日志里有zk相关的超时,就是ZK性能更不上。
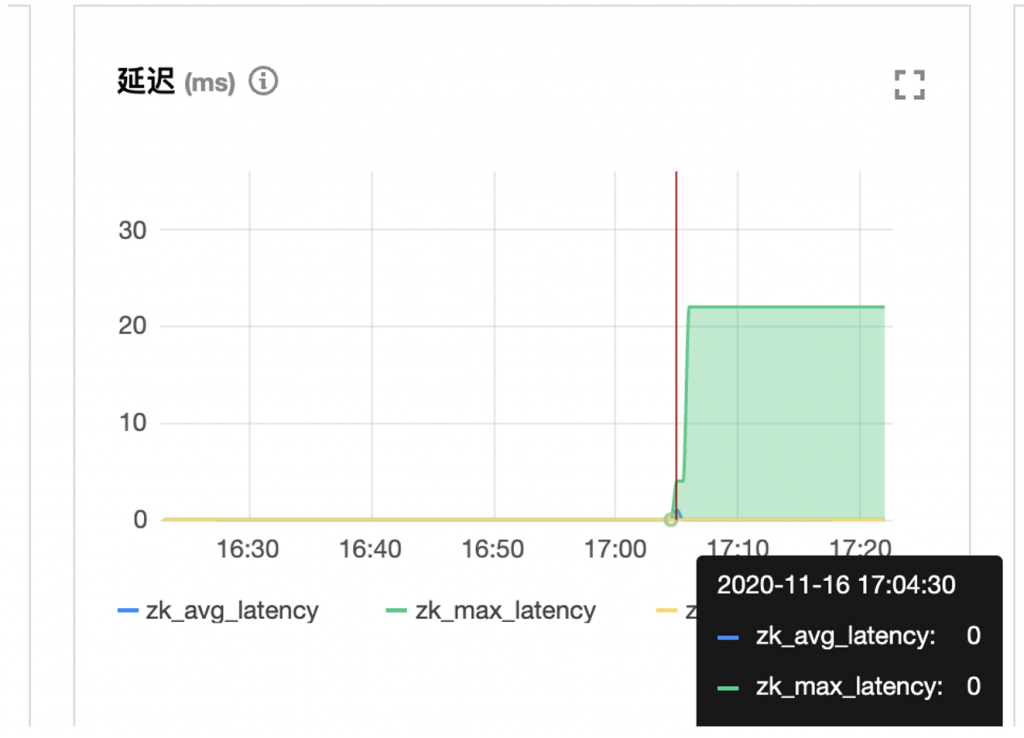
调优策略:
小批次,大批量写入,降低对ZK的QPS,减少的压力,然后横向扩容解决并发问题,不要怕条数多,她设计的原则就是 要你条数多,才能达到最佳性能,1000/s这种 已经触达了ZK的极限了
。
- 如果zk内存使用率较高,zkEnv.sh 修改zk jvm 为8192m,在zoo.cfg 中修改MaxSessionTimeout=120000
- 超时时间socket_timeout 80000

3.Spark insert 的-batch 调大到30000,就是每批次取3万行数据,参数可能是任务的参数

4. metrika.xml的zookeepr配置里调整下参数,调整的ch zk客户端超时,这个值是默认的30s
例如
<zookeeper>
<node>
<host>example1</host>
<port>2181</port>
</node>
<node>
<host>example2</host>
<port>2181</port>
</node>
<session_timeout_ms>30000</session_timeout_ms> –客户端会话的最大超时(以毫秒为单元)
<operation_timeout_ms>10000</operation_timeout_ms>
</zookeeper>
- 重启生效
现在开始写入了。是先写入buffer engine 然后buffer engine 刷新 底层表
写入的数据库和表是:
xxx_dis
buffer的元数据不在zookeeper上,但是跟其他表的读写需要zk支持,就等于是 buffer 表刷底层表 是要走zookeeper. 的。
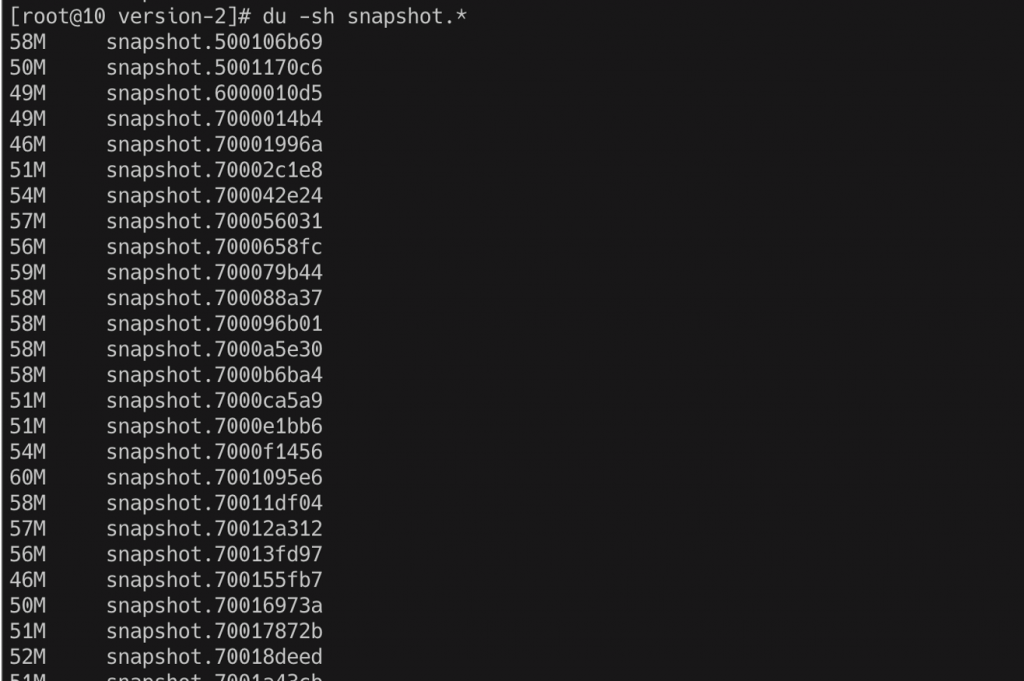
看看ZK机器的snapshot文件大小,如下图,也不大
Buffer表的建表语句方便发下吗? ENGINE = Buffer(‘blower_data_prod’, ‘xxx_info’, 18, 60, 100, 5000000, 6000000, 80000000, 1000000000) 主要就是后面这个吧。前面字段无所谓。



近期评论