
随着运维工作的进一步深入,后期可能涉及到对源码的修改,需要多次重新编译。因此,这一关是绕不过的。
如有疑问,请联系作者,微信 17180081757
版本声明
- 源码:
Apache Hadoop 2.7.3 - 系统:
macOS 10.14.5 - 依赖:
oracle jdk 1.8.0_231Apache Maven 3.6.0libprotoc 2.5.0
编译
核心命令
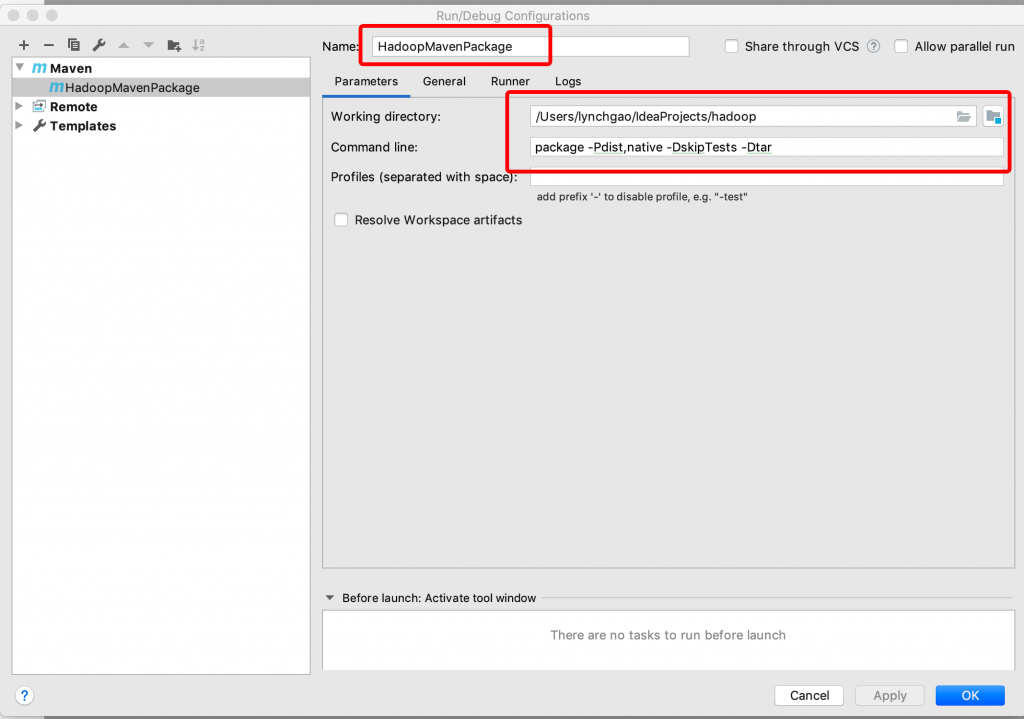
如果使用命令行:package -Pdist,native -DskipTests -Dtar
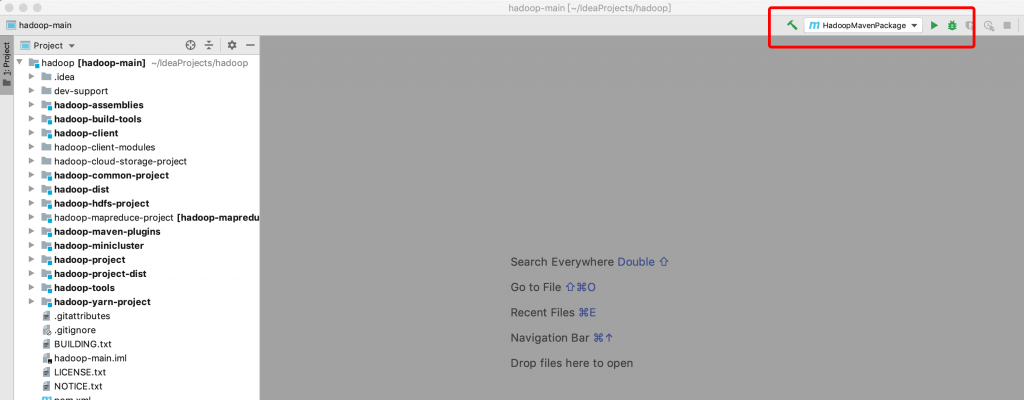
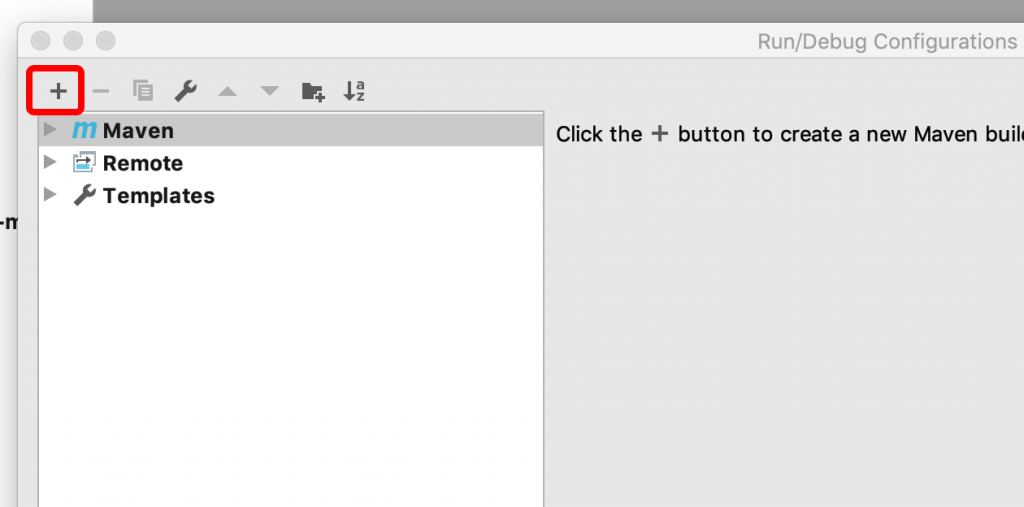
如果使用IDEA 开发工具,右上角,选择“Run/Debug Configuration”,如下图,,点击“+”新增一个,maven的run configuration,Name随便起,主要是Command Line:package -Pdist,native -DskipTests -Dtar
编译Hadoop源码时间比较长
Hadoop源码量巨大、依赖众多,编译时间比较长。
下载jar包和编译protoc是两个大头。编译protoc用了1小时左右,下载jar包+编译Hadoop用了2个多小时。除去这些时间,也需要1小时左右才能编译成功。
还好上半年为了看Yarn的状态机编译过一回,虽然是不完全编译,但也下载了大部分依赖的jar包,并编译安装了protoc(强烈建议编译安装,忘记当时有什么坑来着)。这次只需要继续踩上次剩下的坑了。
不过,鉴于第一次编译时,大部分人都会重复多次才能编译成功,单次编译的时间也没什么意义了。喝杯茶,慢慢来吧。
JDK版本
[ERROR] Failed to execute goal org.apache.maven.plugins:maven-compiler-plugin:2.5.1:compile (default-compile) on project hadoop-annotations: Compilation failure: Compilation failure:[ERROR] /Volumes/Extended/Users/msh/IdealProjects/Git-Study/hadoop/hadoop-common-project/hadoop-annotations/src/main/java/org/apache/hadoop/classification/tools/ExcludePrivateAnnotationsJDiffDoclet.java:[20,22] 错误: 程序包com.sun.javadoc不存在
不明白为啥这个包会不存在,可能是JDK版本问题。google一番,参考解决Mac OS 下编译Hadoop Annotations 程序包com.sun.javadoc找不到问题解决。
验证
在所有的pom.xml里面找设置1.7 jdk的地方:
| 12345678910111213141516 | find . -name pom.xml > tmp/tmp.txt while read filedocnt=0grep ‘1.7’ $file -C2 | while read line; doif [ -n “$line” ]; thenif [ $cnt -eq 0 ]; thenecho “+++file: $file”ficnt=$((cnt+1))echo $linefidonecnt=0done < tmp/tmp.txt |
输出:
| 12345678910111213141516171819 | +++file: ./hadoop-common-project/hadoop-annotations/pom.xml</profile><profile><id>jdk1.7</id><activation>–<activation><jdk>1.7</jdk></activation><dependencies>—-<groupId>jdk.tools</groupId><artifactId>jdk.tools</artifactId><version>1.7</version><scope>system</scope><systemPath>${java.home}/../lib/tools.jar</systemPath>+++file: ./hadoop-project/pom.xml…(略) |
确实./hadoop-common-project/hadoop-annotations/pom.xml中限制了jdk版本。
解决
Mac上的默认JDK是oracle jdk1.8.0_102的,翻了下jdk源码也有这个包。说明不是因为该包实际不存在。
可以尝试修改pom里限制的jdk版本;不过,为了防止使用了deprecated方法等麻烦,这里直接切jdk 1.7,不改pom。
openssl引起编译报错
| 12 | [ERROR] Failed to execute goal org.apache.maven.plugins:maven-antrun-plugin:1.7:run (make) on project hadoop-pipes: An Ant BuildException has occured: exec returned: 1[ERROR] around Ant part …<exec dir=”/Volumes/Extended/Users/msh/IdealProjects/Git-Study/hadoop/hadoop-tools/hadoop-pipes/target/native” executable=”cmake” failonerror=”true”>… @ 5:153 in /Volumes/Extended/Users/msh/IdealProjects/Git-Study/hadoop/hadoop-tools/hadoop-pipes/target/antrun/build-main.xml |
猜测是ant版本问题,重装了jdk1.7适配的ant。
Ant BuildException也是够迷惑的。而且之前猴子电脑配置的jdk1.8,切到1.7之后ant就不能用了(brew安装的ant用1.8jdk编译的,1.7无法解析class文件),重装了适配1.7的ant版本后,ant可以正常使用了,却还是报这个错。。。
结果还是报这个错,打开build-main.xml看,发现是一个cmake命令的配置,copy到终端执行:
| 1 | cmake /Volumes/Extended/Users/msh/IdealProjects/Git-Study/hadoop/hadoop-tools/hadoop-pipes/src/ -DJVM_ARCH_DATA_MODEL=64 |
输出:
| 123456789101112131415 | …(略)CommandLineTools/usr/bin/c++ — works– Detecting CXX compiler ABI info– Detecting CXX compiler ABI info – done– Detecting CXX compile features– Detecting CXX compile features – doneCMake Error at /usr/local/Cellar/cmake/3.6.2/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:148 (message):Could NOT find OpenSSL, try to set the path to OpenSSL root folder in thesystem variable OPENSSL_ROOT_DIR (missing: OPENSSL_INCLUDE_DIR)Call Stack (most recent call first):/usr/local/Cellar/cmake/3.6.2/share/cmake/Modules/FindPackageHandleStandardArgs.cmake:388 (_FPHSA_FAILURE_MESSAGE)/usr/local/Cellar/cmake/3.6.2/share/cmake/Modules/FindOpenSSL.cmake:380 (find_package_handle_standard_args)CMakeLists.txt:20 (find_package) …(略) |
OPENSSL_ROOT_DIR、OPENSSL_INCLUDE_DIR没有设置。echo一下确实没有设置。
解决
Mac自带OpenSSL,然而猴子并不知道哪里算是root,哪里算是include;另外,据说mac计划移除默认的openssl。干脆自己重新安装:
| 1 | brew install openssl |
然后配置环境变量:
| 12 | export OPENSSL_ROOT_DIR=/usr/local/Cellar/openssl/1.0.2nexport OPENSSL_INCLUDE_DIR=$OPENSSL_ROOT_DIR/include 如下是我的配置,请参考: cat ~/.bash_profile export PROTOC=”/usr/local/bin/protoc” export M2_HOME=/Users/lynchgao/apache-maven-3.6.3 export PATH=$PATH:$M2_HOME/bin JAVA_HOME=/Library/Java/JavaVirtualMachines/jdk1.8.0_231.jdk/Contents/Home PATH=$JAVA_HOME/bin:$PATH:. CLASSPATH=$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar:. export JAVA_HOME export PATH export CLASSPATH export OPENSSL_ROOT_DIR=/usr/local/Cellar/openssl1.0.2k export PATH=OPENSSL_ROOT_DIR/bin:$PATH export OPENSSL_INCLUDE_DIR=$OPENSSL_ROOT_DIR/include export OPENSSL_LIB_DIR=$OPENSSL_ROOT_DIR/lib |
继续编译,发现编译hadoop-pipes时候,报错“around Ant part …<exec dir=”/Users/lynchgao/IdeaProjects/hadoop/hadoop-tools/hadoop-pipes/target/native” executable=”make”
按照上面的方法,进入指定目录执行make
cd /Users/lynchgao/IdeaProjects/hadoop/hadoop-tools/hadoop-pipes/target/native
执行make
报错“/usr/local/opt/openssl@1.1/include/openssl/ossl_typ.h:102:16: note: forward
declaration of ‘hmac_ctx_st’”
网上搜了一下,说是版本冲突,查了一下hadoop 2.7.3 用的是openssl1.0.2k,
从git上拉取代码https://github.com/openssl/openssl/tree/OpenSSL_1_0_2k
编译mac 64位版本版本需要注意,darwin64-x86_64-cc 是编译64位
sudo ./Configure darwin64-x86_64-cc –prefix=/usr/local/Cellar/openssl1.0.2k
make
make install
然后替换brew 默认安装的路径,替换brew默认路径,是因为hadoop-pipeline c代码 include时候需要找openssl
mv /usr/local/opt/openssl@1.1/ /usr/local/opt/openssl@1.1_bak/
cp -rf /usr/local/Cellar/openssl1.0.2k /usr/local/opt/openssl@1.1
如果从命令行执行 openssl version还是高版本,请联系我
maven仓库不稳定
| 1 | [ERROR] Failed to execute goal on project hadoop-aws: Could not resolve dependencies for project org.apache.hadoop:hadoop-aws:jar:2.6.0: Could not transfer artifact com.amazonaws:aws-java-sdk:jar:1.7.4 from/to central (https://repo.maven.apache.org/maven2): GET request of: com/amazonaws/aws-java-sdk/1.7.4/aws-java-sdk-1.7.4.jar from central failed: SSL peer shut down incorrectly -> [Help 1] |
出现类似“Could not resolve dependencies”、“SSL peer shut down incorrectly”等语句,一般是maven不稳定,换个稳定的maven源,或者重新编译多试几次。
更换旧的Openssl办法
不过,我们还有最后一步,那就是当我们使用openssl时,使用的是我们用homebrew新下载的openssl。为了达到这个目的,我们有两种方法。
将homebrew下载的openssl软链接到/usr/bin/openssl目录下。这里,我们先将它保存一份老的,然后再软链接新下载的。
$ mv /usr/bin/openssl /usr/bin/openssl_old
mv: rename /usr/bin/openssl to /usr/bin/openssl_old: Operation not permitted
$ ln -s /usr/local/Cellar/openssl/1.0.2p/bin/openssl /usr/bin/openssl
ln: /usr/bin/openssl: Operation not permitted
Operation not permitted提示没有权限操作,对/usr/bin目录下的东西,我已经遇到过几次这个问题了,于是继续google,在stackoverflow上找到了Operation Not Permitted when on root El capitan (rootless disabled)。
重启系统,当启动的时候我们同时按下cmd+r进入Recovery模式,之后选择实用工具 => 终端,在终端输入如下命令,接口文件系统的锁定,并且重启电脑(cmd+r后,会进入另外一个选择系统启动的界面,在这个界面里面不要马上重新启动,先找到终端,在終端中输入csrutil disable):
$ csrutil disable
$ reboot最后,我们执行前面两个命令,查看版本。
$ sudo mv /usr/bin/openssl /usr/bin/openssl_old
$ sudo ln -s /usr/local/Cellar/openssl/1.0.2p/bin/openssl /usr/bin/openssl
$ openssl version
OpenSSL 1.0.2p 14 Aug 2018
➜ which openssl
/usr/local/opt/openssl/bin/openssl这样,我们的openssl升级成功了。不过,为了安全起见,我还是重新启动电脑,然后重新开启了csrutil。
csrutil enable
reboot其他
历史遗留坑
上次编译有个小坑,是Hadoop源码里的历史遗留问题。
编译过程中会在$JAVA_HOME/Classes下找一个并不存在的jar包classes.jar,实际上需要的是$JAVA_HOME/lib/tools.jar,加个软链就好(注意mac加软链时与linux的区别)。
因此上次编译猴子已经修复了这个问题,这里就不复现了。具体可以看这篇mac下编译Hadoop
没有SKIPTESTS
没有skipTests的话,至少会在测试过程中以下错误:
| 1234567891011 | [ERROR] Failed to execute goal org.apache.maven.plugins:maven-surefire-plugin:2.16:test (default-test) on project hadoop-auth: There are test failures.[ERROR][ERROR] Please refer to /Volumes/Extended/Users/msh/IdealProjects/Git-Study/hadoop/hadoop-common-project/hadoop-auth/target/surefire-reports for the individual test results. Results : Tests in error:TestKerberosAuthenticator.testAuthenticationHttpClientPost:157 » ClientProtocolTestKerberosAuthenticator.testAuthenticationHttpClientPost:157 » ClientProtocol Tests run: 92, Failures: 0, Errors: 2, Skipped: 0 |
可以暂时忽略这些相关错误,skipTests跳过测试,能追踪源码了解主要过程即可。
启动伪分布式“集群”
编译成功后,在hadoop-dist模块的target目录下,生成了各种发行版。选择hadoop-2.6.0.tar.gz,找个地方解压。
配置SSH 无密码链接
如果没有安装SSH,执行下面命令安装
# Install ssh
$ apt install ssh
# Check 22 port
$ netstat –nat
回到用户目录
即 /home/ubuntu (ubuntu 是当前用户的主目录)
$ cd ~执行 ssh-keygen 命令, 一直回车。
$ ssh-keygen -t rsa
在当前用户目录下有个隐藏目录 .ssh 目录 ,进入该目录
$ cd .ssh里面有 id_rsa.pub 文件, 将其赋值到 authorized_keys 文件
$ cp id_rsa.pub authorized_keys然后再测试 SSH登录

当你尝试连接本机的时候就可以直接链接不需要登录。
如果你想直接链接其他VM, 只需要将其他机器上的 id_rsa.pub 添加到authorized_keys, 这样就可以直接ssh 链接过去而不需要输入密码。 这个在后面启动hadoop 时候就很有用,启动服务就不用输入密码。
配置IP
$ sudo vim /etc/hosts
# 通过此命令配置IP映射第一个VM的 mster
10.0.1.6 slave1
10.0.1.10 slave2
10.0.1.12 master第二个VM的 slave1
10.0.1.6 slave1
10.0.1.10 slave2
10.0.1.12 master第三个VM的 slave2
10.0.1.6 slave1
10.0.1.10 slave2
10.0.1.12 master配置Hadoop
首先解压 hadoop 文件
$ tar -xvf hadoop-2.7.3.tar.gz
咱们这个案例是把hadoop编译好的包拷出来使用
cd /Users/lynchgao/IdeaProjects/hadoop/hadoop-dist/target
解压完成之后进入 配置文件所在目录即 hadoop-2.7.3 目录下 etc/hadoop 内
cd /data/install/apache/hadoop-2.7.3/etc/hadoop/接下来要配置以下几个文件:
core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、slaves、hadoop-env.sh、yarn-env.sh
hadoop-env.sh和yarn-env.sh 配置 jdk 环境
# The java implementation to use.
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/home/ubuntu/developer/jdk1.8.0_121core-site.xml
<!-- Put site-specific property overrides in this file. -->
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/home/ubuntu/developer/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131702</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/home/ubuntu/developer/hadoop-2.7.3/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/home/ubuntu/developer/hadoop-2.7.3/hdfs/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:9001</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.namenode.datanode.registration.ip-hostname-check</name>
<value>false</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
</configuration>
yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.auxservices.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>master:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>master:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>master:8031</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>master:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
</configuration>
mapred-site.xml
默认没有这个文件 但是提供了个模板 mapred-site.xml.template
通过这个模板复制一个
$ cp etc/hadoop/mapred-site.xml.template etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>
slaves
slave1
slave2
将配置好的hadoop 文件夹复制给其他节点(slave1 和slave2)
scp -r /home/ubuntu/developer/hadoop-2.7.3 ubuntu@slave1:/home/ubuntu/developer/hadoop-2.7.3
scp -r /home/ubuntu/developer/hadoop-2.7.3 ubuntu@slave2:/home/ubuntu/developer/hadoop-2.7.3
运行启动Hadoop
1- 初始化hadoop(清空hdfs数据):
rm -rf /home/ubuntu/developer/hadoop-2.7.3/hdfs/*
rm -rf /home/ubuntu/developer/hadoop-2.7.3/tmp/*
/home/ubuntu/developer/hadoop-2.7.3/bin/hdfs namenode -format
2- 启动hdfs,yarn
/home/ubuntu/developer/hadoop-2.7.3/sbin/start-dfs.sh
/home/ubuntu/developer/hadoop-2.7.3/sbin/start-yarn.sh3- 停止hdfs,yarn
/home/ubuntu/developer/hadoop-2.7.3/sbin/stop-dfs.sh
/home/ubuntu/developer/hadoop-2.7.3/sbin/stop-yarn.sh
4- 检查是否成功
在 master 终端敲 jps 命令

master-jps.png
在 slave 终端敲 jps 命令

slave-jps.png
或者在master 节点看 report
$ bin/hdfs dfsadmin -report
到此, hadoop 可以正常启动。
一些常用命令
#列出HDFS下的文件
hdfs dfs -ls
#列出HDFS下某个文档中的文件
hdfs dfs -ls in
#上传文件到指定目录并且重新命名,只有所有的DataNode都接收完数据才算成功
hdfs dfs -put test1.txt test2.txt
#从HDFS获取文件并且重新命名为getin,
同put一样可操作文件也可操作目录
hdfs dfs -get in getin
#删除指定文件从HDFS上
hdfs dfs -rmr out
#查看HDFS上in目录的内容
hdfs dfs -cat in/*
#查看HDFS的基本统计信息
hdfs dfsadmin -report
#退出安全模式
hdfs dfsadmin -safemode leave
#进入安全模式
hdfs dfsadmin -safemode enter
运行WordCount官方例子
- 在 /home/ubuntu 下建立一个文件夹input, 并放几个txt文件在内
- 切换到 hadoop-2.7.3目录内
- 给hadoop创建一个 wc_input文件夹
$ bin/hdfs dfs -mkdir /wc_input- 将 /home/ubuntu/input 内的文件传到hadoop /wc_input 内
$ bin/hdfs dfs –put /home/ubuntu/input* /wc_input$ bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /wc_input /wc_oput- 查看结果
$ bin/hdfs dfs -ls /wc_output
$ bin/hdfs dfs -ls /wc_output/part-r-00000- 在浏览器上查看
http://your-floating-ip:50070/dfshealth.html
但是在此之前可能需要开通端口,为了简便我在OpenStack上将所有端口开通。

tcp-ports.png







近期评论