
作者:云邪(Jark)
原文链接:http://wuchong.me/blog/2018/11/09/flink-tech-evolution-introduction/
Apache Flink 介绍
Apache Flink 是近年来越来越流行的一款开源大数据计算引擎,它同时支持了批处理和流处理,也能用来做一些基于事件的应用。使用官网的一句话来介绍 Flink 就是 “Stateful Computations Over Streams”。
首先 Flink 是一个纯流式的计算引擎,它的基本数据模型是数据流。流可以是无边界的无限流,即一般意义上的流处理。也可以是有边界的有限流,这样就是批处理。因此 Flink 用一套架构同时支持了流处理和批处理。其次,Flink 的一个优势是支持有状态的计算。如果处理一个事件(或一条数据)的结果只跟事件本身的内容有关,称为无状态处理;反之结果还和之前处理过的事件有关,称为有状态处理。稍微复杂一点的数据处理,比如说基本的聚合,数据流之间的关联都是有状态处理。
Apache Flink 基石
Apache Flink 之所以能越来越受欢迎,我们认为离不开它最重要的四个基石:Checkpoint、State、Time、Window。
首先是Checkpoint机制,这是 Flink 最重要的一个特性。Flink 基于 Chandy-Lamport 算法实现了分布式一致性的快照,从而提供了 exactly-once 的语义。在 Flink 之前的流计算系统(如 Strom,Samza)都没有很好地解决 exactly-once 的问题。提供了一致性的语义之后,Flink 为了让用户在编程时能够更轻松、更容易地去管理状态,引入了托管状态(managed state)并提供了 API 接口,让用户使用起来感觉就像在用 Java 的集合类一样。除此之外,Flink 还实现了 watermark 的机制,解决了基于事件时间处理时的数据乱序和数据迟到的问题。最后,流计算中的计算一般都会基于窗口来计算,所以 Flink 提供了一套开箱即用的窗口操作,包括滚动窗口、滑动窗口、会话窗口,还支持非常灵活的自定义窗口以满足特殊业务的需求。
Flink API 历史变迁
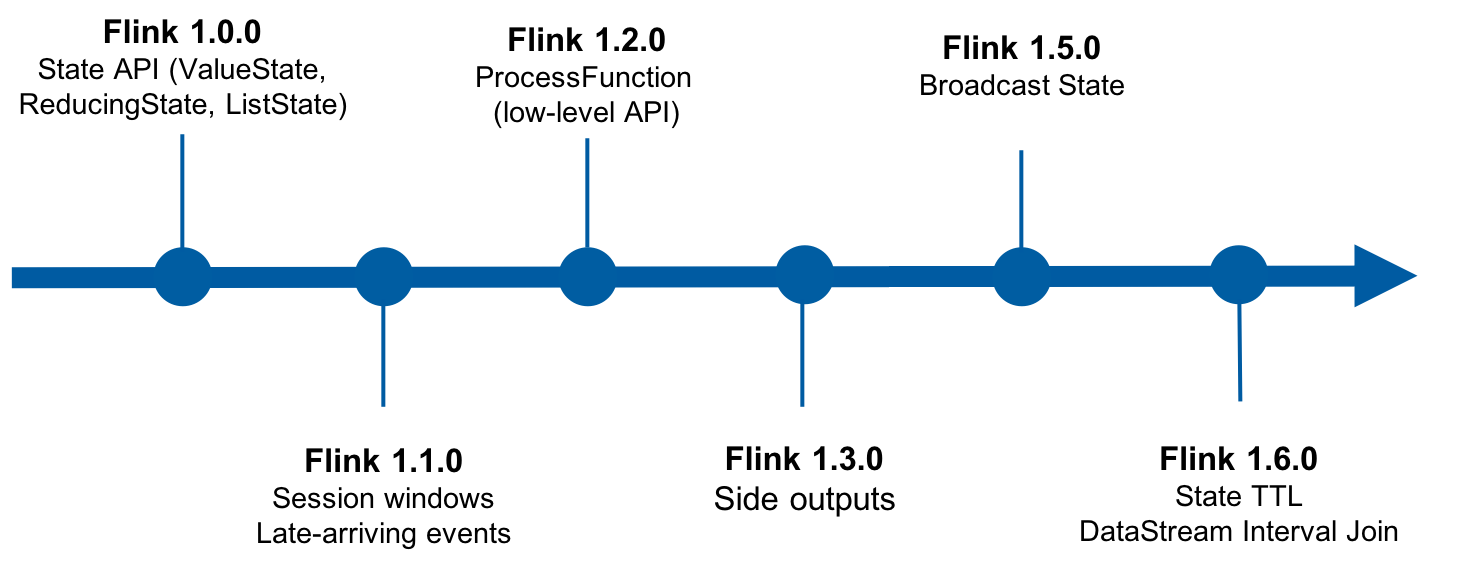
在 Flink 1.0.0 时期,加入了 State API,即 ValueState、ReducingState、ListState 等等。State API 可以认为是 Flink 里程碑式的创新,它能够让用户像使用 Java 集合一样地使用 Flink State,却能够自动享受到状态的一致性保证,不会因为故障而丢失状态。包括后来 Apache Beam 的 State API 也从中借鉴了很多。
在 Flink 1.1.0 时期,支持了 Session Window 以及迟到数据容忍的功能。
在 Flink 1.2.0 时期,提供了 ProcessFunction,这是一个 Lower-level 的API,用于实现更高级更复杂的功能。它除了能够注册各种类型的 State 外,还支持注册定时器(支持 EventTime 和 ProcessingTime),常用于开发一些基于事件、基于时间的应用程序。
在 Flink 1.3.0 时期,提供了 Side Output 功能。算子的输出一般只有一种输出类型,但是有些时候可能需要输出另外的类型,比如除了输出主流外,还希望把一些异常数据、迟到数据以侧边流的形式进行输出,并分别交给下游不同节点进行处理。简而言之,Side Output 支持了多路输出的功能。
在 Flink 1.5.0 时期,加入了BroadcastState。BroadcastState是对 State API 的一个扩展。它用来存储上游被广播过来的数据,这个 operator 的每个并发上存的BroadcastState里面的数据都是一模一样的,因为它是从上游广播而来的。基于这种State可以比较好地去解决 CEP 中的动态规则的功能,以及 SQL 中不等值Join的场景。
在 Flink 1.6.0 时期,提供了State TTL功能、DataStream Interval Join功能。State TTL实现了在申请某个State时候可以在指定一个生命周期参数(TTL),指定该state过了多久之后需要被系统自动清除。在这个版本之前,如果用户想要实现这种状态清理操作需要使用ProcessFunction注册一个Timer,然后利用Timer的回调手动把这个State清除。从该版本开始,Flink框架可以基于TTL原生地解决这件事情。另外 DataStream Interval Join 功能也叫做 区间Join。例如左流的每一条数据去Join右流前后5分钟之内的数据,这种就是5分钟的区间Join。
Flink High-Level API 历史变迁
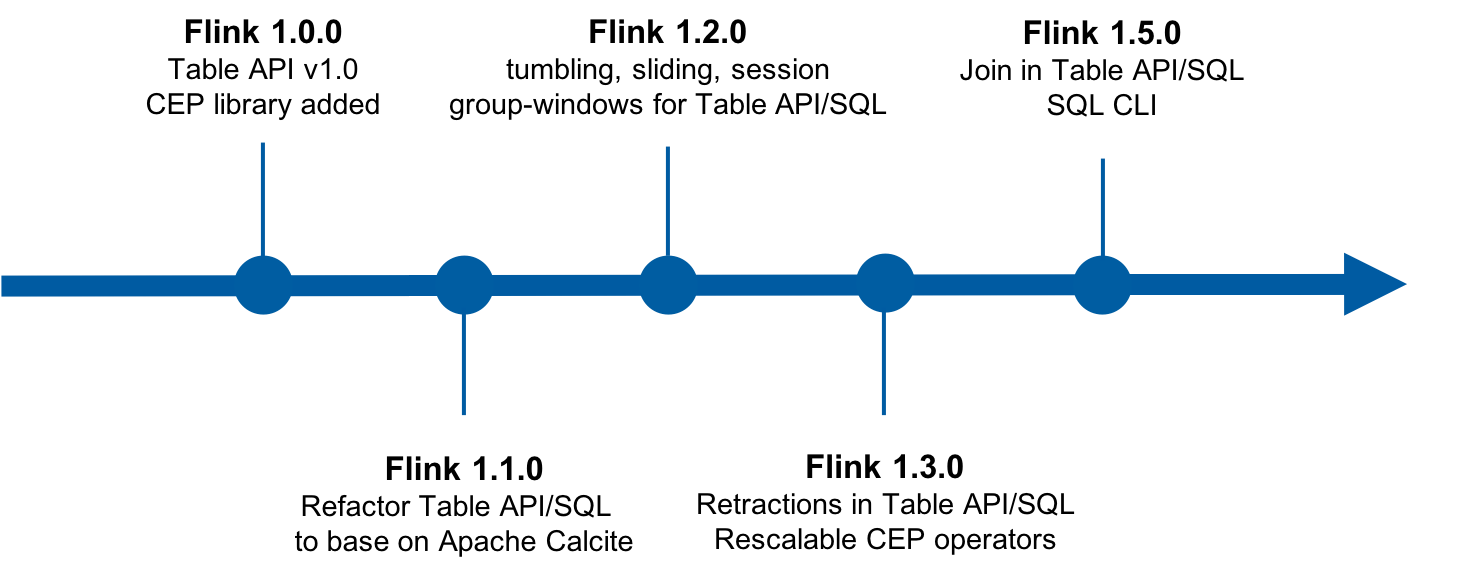
在 Flink 1.0.0 时期,Table API (结构化数据处理API)和 CEP(复杂事件处理API)这两个框架被首次加入到仓库中。Table API 是一种结构化的高级 API,支持 Java 语言和 Scala 语言,类似于 Spark 的 DataFrame API。但是当时社区对于 SQL 的需求很大,而 SQL 和 Table API 非常相近,他们都是一种处理结构化数据的语言,实现上可以共用很多内容。所以在 Flink 1.1.0里面,社区基于Apache Calcite对整个 Table 模块做了重构,使得同时支持了 Table API 和 SQL 并共用了大部分代码。
在 Flink 1.2.0 时期,社区在Table API和SQL上支持丰富的内置窗口操作,包括Tumbling Window、Sliding Window、Session Window。
在 Flink 1.3.0 时期,社区首次提出了Dynamic Table这个概念,借助Dynamic Table,流和批之间可以相互进行转换。流可以是一张表,表也可以是一张流,这是流批统一的基础之一。其中Retraction机制是实现Dynamic Table的基础,基于Retraction才能够正确地实现多级Aggregate、多级Join,才能够保证流式 SQL 的语义与结果的正确性。另外,在该版本中还支持了 CEP 算子的可伸缩容(即改变并发)。
在 Flink 1.5.0 时期,在 Table API 和 SQL 上支持了Join操作,包括无限流的 Join 和带窗口的 Join。还添加了 SQL CLI 支持。SQL CLI 提供了一个类似Shell命令的对话框,可以交互式执行查询。
Flink Checkpoint & Recovery 历史变迁

Checkpoint机制在Flink很早期的时候就已经支持,是Flink一个很核心的功能,Flink 社区也一直努力提升 Checkpoint 和 Recovery 的效率。
在 Flink 1.0.0 时期,提供了 RocksDB 状态后端的支持,在这个版本之前所有的状态数据只能存在进程的内存里面,JVM 内存是固定大小的,随着数据越来越多总会发生 FullGC 和 OOM 的问题,所以在生产环境中很难应用起来。如果想要存更多数据、更大的State就要用到 RocksDB。RocksDB是一款基于文件的嵌入式数据库,它会把数据存到磁盘,同时又提供高效的读写性能。所以使用RocksDB不会发生OOM这种事情。
在 Flink 1.1.0 时期,支持了 RocksDB Snapshot 的异步化。在之前的版本,RocksDB 的 Snapshot 过程是同步的,它会阻塞主数据流的处理,很影响吞吐量。在支持异步化之后,吞吐量得到了极大的提升。
在 Flink 1.2.0 时期,通过引入KeyGroup的机制,支持了 KeyedState 和 OperatorState 的可扩缩容。也就是支持了对带状态的流计算任务改变并发的功能。
在 Flink 1.3.0 时期,支持了 Incremental Checkpoint (增量检查点)机制。Incemental Checkpoint 的支持标志着 Flink 流计算任务正式达到了生产就绪状态。增量检查点是每次只将本次 checkpoint 期间新增的状态快照并持久化存储起来。一般流计算任务,GB 级别的状态,甚至 TB 级别的状态是非常常见的,如果每次都把全量的状态都刷到分布式存储中,这个效率和网络代价是很大的。如果每次只刷新增的数据,效率就会高很多。在这个版本里面还引入了细粒度的recovery的功能,细粒度的recovery在做恢复的时候,只需要恢复失败节点的联通子图,不用对整个 Job 进行恢复,这样便能够提高恢复效率。
在 Flink 1.5.0 时期,引入了本地状态恢复的机制。因为基于checkpoint机制,会把State持久化地存储到某个分布式存储,比如HDFS,当发生 failover 的时候需要重新把数据从远程HDFS再下载下来,如果这个状态特别大那么下载耗时就会较长,failover 恢复所花的时间也会拉长。本地状态恢复机制会提前将状态文件在本地也备份一份,当Job发生failover之后,恢复时可以在本地直接恢复,不需从远程HDFS重新下载状态文件,从而提升了恢复的效率。
Flink Runtime 历史变迁
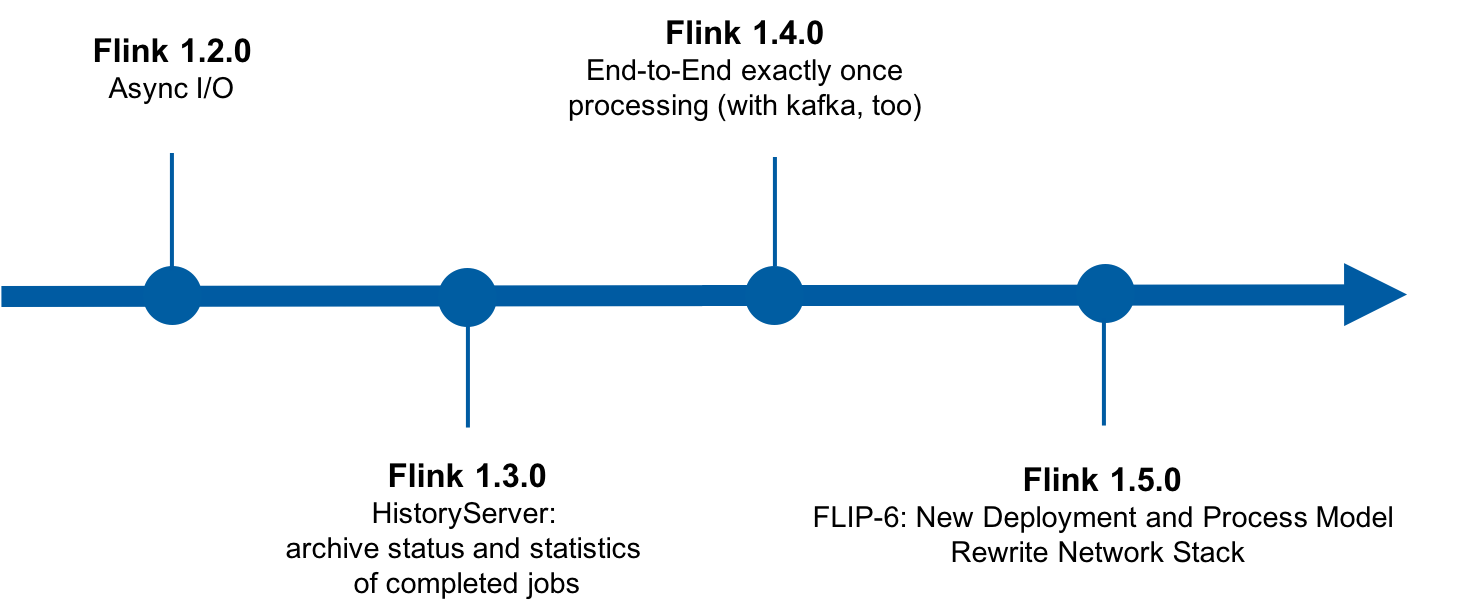
在 Flink 1.2.0 时期,提供了Async I/O功能。Async I/O 是阿里巴巴贡献给社区的一个呼声非常高的特性,主要目的是为了解决与外部系统交互时网络延迟成为了系统瓶颈的问题。例如,为了关联某些字段需要查询外部 HBase 表,同步的方式是每次查询的操作都是阻塞的,数据流会被频繁的I/O请求卡住。当使用异步I/O之后就可以同时地发起N个异步查询的请求,不会阻塞主数据流,这样便提升了整个job的吞吐量,提升CPU利用率。
在 Flink 1.3.0 时期,引入了HistoryServer的模块。HistoryServer主要功能是当job结束以后,会把job的状态以及信息都进行归档,方便后续开发人员做一些深入排查。
在 Flink 1.4.0 时期,提供了端到端的 exactly-once 的语义保证。Exactly-once 是指每条输入的数据只会作用在最终结果上有且只有一次,即使发生软件或硬件的故障,不会有丢数据或者重复计算发生。而在该版本之前,exactly-once 保证的范围只是 Flink 应用本身,并不包括输出给外部系统的部分。在 failover 时,这就有可能写了重复的数据到外部系统,所以一般会使用幂等的外部系统来解决这个问题。在 Flink 1.4 的版本中,Flink 基于两阶段提交协议,实现了端到端的 exactly-once 语义保证。内置支持了 Kafka 的端到端保证,并提供了 TwoPhaseCommitSinkFunction 供用于实现自定义外部存储的端到端 exactly-once 保证。
在 Flink 1.5.0 时期,Flink 发布了新的部署模型和处理模型(FLIP6)。新部署模型的开发工作已经持续了很久,该模型的实现对Flink核心代码改动特别大,可以说是自 Flink 项目创建以来,Runtime 改动最大的一次。简而言之,新的模型可以在YARN, MESOS调度系统上更好地动态分配资源、动态释放资源,并实现更高的资源利用率,还有提供更好的作业之间的隔离。
除了 FLIP6 的改进,在该版本中,还对网站栈做了重构。重构的原因是在老版本中,上下游多个 task 之间的通信会共享同一个 TCP connection,导致某一个 task 发生反压时,所有共享该连接的 task 都会被阻塞,反压的粒度是 TCP connection 级别的。为了改进反压机制,Flink应用了在解决网络拥塞时一种经典的流控方法——基于Credit的流量控制。使得流控的粒度精细到具体某个 task 级别,有效缓解了反压对吞吐量的影响。
总结
Flink 同时支持了流处理和批处理,目前流计算的模型已经相对比较成熟和领先,也经历了各个公司大规模生产的验证。社区在接下来将继续加强流计算方面的性能和功能,包括对 Flink SQL 扩展更丰富的功能和引入更多的优化。另一方面也将加大力量提升批处理、机器学习等生态上的能力。
关注微信公众号 爱解决,更多技术大牛帮你解决问题!


近期评论